
PDTs no LookML: O Segredo para Dashboards Mais Rápidos e Inteligentes
No universo do BI, turbinar seus relatórios e análises é crucial. No Looker, uma ferramenta poderosa para isso são as Derived Tables, ou PDTs (Persistent Derived Tables). Pense nelas como tabelas virtuais criadas a partir de consultas SQL personalizadas, direto no seu LookML. Elas são a chave para lidar com lógicas de dados complexas e garantir que seus dashboards carreguem na velocidade da luz.
Por que usar Derived Tables?
- Lógica SQL Caprichada: Quando você precisa de joins, agregações ou cálculos que vão além do básico do LookML.
- Performance Turbinada: Para pré-calcular e armazenar resultados, acelerando consultas demoradas.
- Visualização Simplificada: Como uma tabela ou view virtual dentro do Looker, facilitando a modelagem.
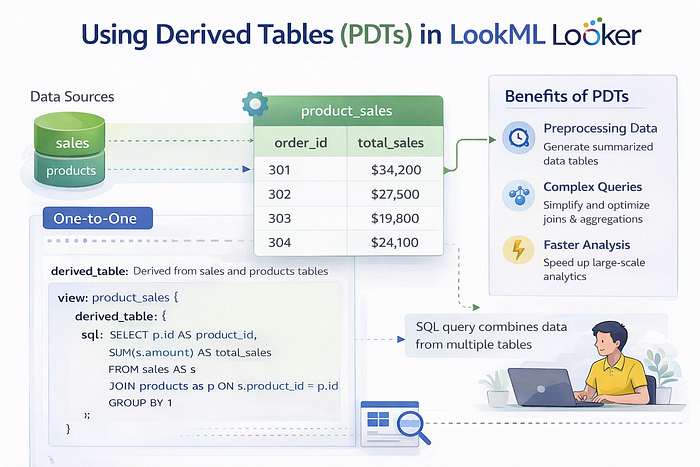
O Que São Essas Tal de Derived Tables?
Basicamente, uma Derived Table é uma consulta SQL que você embuti em uma view do LookML. Ela funciona como uma fonte de dados para o seu modelo. Você pode, inclusive, definir dimensões e medidas sobre ela, tratando-a como uma tabela comum.
Exemplo na Prática:
Imagine que você quer juntar dados de usuários e seus pedidos para ter um resumo rápido. Com uma Derived Table, isso fica simples:
view: user_orders {
derived_table: {
sql:
SELECT
users.id AS user_id,
users.name,
COUNT(orders.id) AS total_orders,
SUM(orders.amount) AS total_revenue
FROM users
LEFT JOIN orders ON users.id = orders.user_id
GROUP BY 1, 2 ;;
}
dimension: user_id { primary_key: yes }
dimension: name {}
measure: total_orders { type: sum; sql: ${TABLE}.total_orders ;; }
measure: total_revenue { type: sum; sql: ${TABLE}.total_revenue ;; }
}
Nesse código, criamos uma tabela temporária que junta informações de usuários com seus pedidos, calcula o total de pedidos e a receita. Depois, definimos as dimensões e medidas para usar esses dados nos seus Explorations.
Tipos de Derived Tables: Qual a Diferença?
O Looker oferece dois jeitos de trabalhar com Derived Tables:
- Derived Tables Efêmeras: Elas são criadas na hora que uma consulta é executada e só existem na memória. Isso significa que elas rodam toda vez que um Explore ou dashboard é aberto. São ótimas para datasets menores ou cálculos simples.
- Persistent Derived Tables (PDTs): Essas são materializadas, ou seja, salvas como tabelas temporárias no seu banco de dados. Elas podem ser reconstruídas em um schedule ou quando os dados de origem mudam, o que melhora muito a performance em consultas grandes e complexas. Para usar PDTs, você precisa de espaço de armazenamento e permissão de escrita no banco.
Exemplo de PDT com tempo de persistência:
derived_table: {
sql: SELECT * FROM bigquery_dataset.sales_summary ;;
persist_for: "24 hours"
}
Aqui, a consulta é salva e atualizada a cada 24 horas, garantindo agilidade sem sobrecarregar o banco em cada consulta.
Criando uma PDT e Gerenciando seu Ciclo de Vida
Uma PDT é uma Derived Table que o Looker fisicamente cria e armazena no seu banco de dados. Ela se auto-reconstrói com base em gatilhos ou agendas. O parâmetro persist_for define por quanto tempo os dados serão mantidos antes de serem atualizados. Por exemplo, persist_for: "12 hours" garante que a PDT seja reconstruída a cada 12 horas.
Exemplo de PDT com persist_for:
view: revenue_summary {
derived_table: {
sql:
SELECT
customer_id,
SUM(amount) AS total_revenue,
COUNT(order_id) AS total_orders
FROM analytics.orders
WHERE order_date >= CURRENT_DATE - INTERVAL 90 DAY
GROUP BY 1 ;;
persist_for: "12 hours"
}
dimension: customer_id {}
measure: total_revenue { type: sum; sql: ${TABLE}.total_revenue ;; }
measure: total_orders { type: sum; sql: ${TABLE}.total_orders ;; }
}
Quando o Looker cria uma PDT, ele executa a sua query SQL, gera uma tabela temporária no seu data warehouse e armazena os resultados. Tabelas PDT geralmente seguem um padrão de nomenclatura como _looker_tmp_ ou _looker_pdt_.
Gatilhos Inteligentes com Data Groups
Para ter um controle ainda maior sobre a atualização das suas PDTs, você pode usar datagroup_trigger. Isso garante que a PDT só seja reconstruída quando os dados de origem realmente mudarem, em vez de seguir um cronograma fixo.
Exemplo de Data Group Trigger:
datagroup: sales_data_refresh {
sql_trigger: SELECT MAX(updated_at) FROM analytics.sales ;;
max_cache_age: "24 hours"
}
view: sales_summary {
derived_table: {
sql:
SELECT region, SUM(amount) AS total_sales
FROM analytics.sales
GROUP BY 1 ;;
datagroup_trigger: sales_data_refresh
}
}
Com isso, a PDT será atualizada sempre que o campo updated_at na tabela analytics.sales for modificado, garantindo que seus dados estejam sempre frescos sem gastar recursos desnecessariamente.
Integrando PDTs nos seus Explorations
Depois de definir sua Derived Table como uma view, você pode juntá-la em um Explore como faria com qualquer outra tabela. Isso permite que os usuários explorem dados complexos sem precisar escrever SQL manualmente.
Exemplo de Join em Explore:
explore: customers {
join: revenue_summary {
type: left_outer
sql_on: ${customers.id} = ${revenue_summary.customer_id} ;;
relationship: one_to_one
}
}
Isso permite aos seus analistas verem a receita total por cliente de forma direta e intuitiva.
Performance e Boas Práticas
Use PDTs para:
- Datasets grandes com cálculos pesados.
- Joins e agregações complexas.
- Tabelas de resumo que precisam ser reutilizadas.
Evite PDTs para:
- Datasets pequenos ou métricas em tempo real.
- Dados que mudam com muita frequência (o custo de reconstrução pode ser alto).
Dica de Ouro: Use explore_source para criar PDTs a partir de outros Explorations, gerando resumos ainda mais poderosos e reutilizáveis.
Um Cenário Real: Resumo de Vendas Diário
Seus analistas frequentemente precisam do total de vendas por região e por mês. Em vez de calcular isso toda vez, você cria uma PDT:
view: monthly_sales_summary {
derived_table: {
sql:
SELECT
DATE_TRUNC(order_date, MONTH) AS month,
region,
SUM(amount) AS total_sales
FROM analytics.orders
GROUP BY 1, 2 ;;
persist_for: "24 hours"
}
dimension: month { type: date }
dimension: region {}
measure: total_sales { type: sum; sql: ${TABLE}.total_sales ;; }
}
Com isso, a PDT é atualizada diariamente, e seus analistas podem explorar as vendas mensais rapidamente, sem esperar pela agregação completa a cada consulta.
Melhores Práticas para Mandar Bem com PDTs
- Mantenha seu SQL limpo e otimizado.
- Use
persist_forcom sabedoria: equilibre o frescor dos dados com a performance. - Teste suas PDTs com dados de produção para garantir que elas aguentam o tranco.
- Monitore falhas de PDTs no painel de Admin do Looker.
- Evite criar cadeias muito longas de PDTs para não complicar as dependências.
- Documente a lógica no LookML com comentários claros.
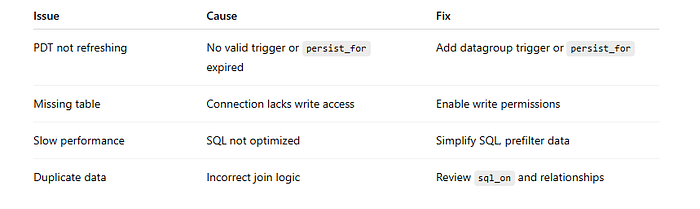
Troubleshooting de PDTs
Problemas com PDTs são comuns, mas geralmente fáceis de resolver. O painel de administração do Looker é seu melhor amigo para identificar e corrigir erros de construção ou consulta.
Exemplo Prático: Marketing Analytics
Você tem tabelas de impressões, cliques e conversões. Precisa calcular métricas diárias de campanha como CTR e taxa de conversão. Uma PDT é a solução:
view: campaign_metrics {
derived_table: {
sql:
SELECT
campaign_id,
DATE(event_time) AS date,
COUNT(DISTINCT impression_id) AS impressions,
COUNT(DISTINCT click_id) AS clicks,
COUNT(DISTINCT conversion_id) AS conversions
FROM marketing_data.events
GROUP BY 1, 2 ;;
persist_for: "1 day"
}
}
Isso acelera drasticamente dashboards como o de “Desempenho Diário de Campanhas”.

Resumo da Ópera
Derived Tables, e especialmente as PDTs, são ferramentas incríveis no Looker. Elas simplificam lógicas complexas, otimizam a performance dos seus dashboards e garantem que seus dados estejam sempre disponíveis e rápidos para análise. Pense nas PDTs como a sua camada de dados personalizada dentro do Looker, pronta para desmistificar qualquer conjunto de dados.
Principais pontos:
- Derived Tables facilitam a vida com dados complexos.
- PDTs aceleram seus relatórios ao guardar resultados no banco.
datagroup_triggeroferece atualizações dinâmicas.- Testar e monitorar é essencial para manter tudo funcionando.
- PDTs são a sua camada de dados customizada no Looker.
chat_bubble Comentários (0)
Nenhum comentário ainda. Seja o primeiro a comentar!
Deixe seu comentário