
PDTs no Looker: Acelerando Suas Análises de Dados e Simplificando o SQL
No universo das análises de dados, a velocidade e a eficiência são cruciais. As Tabelas Derivadas Persistentes (PDTs) emergem como um superpoder dentro do Looker, prometendo deixar suas consultas mais rápidas, o código SQL mais enxuto e a escalabilidade para datasets gigantes uma realidade.
Entendendo o Conceito de PDTs
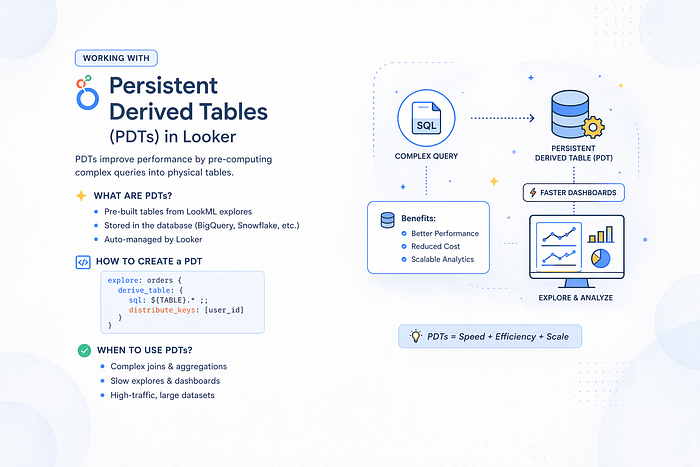
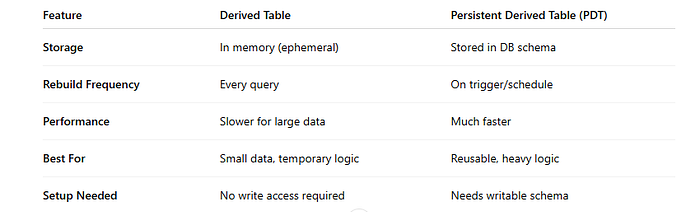
Imagine ter uma versão "cacheada" de uma tabela criada a partir de um SQL complexo. É exatamente isso que as PDTs fazem: elas materializam (guardam fisicamente no seu banco de dados) os resultados de uma consulta SQL. Em vez de o Looker executar o mesmo SQL repetidamente, ele simplesmente acessa essa tabela pré-calculada. Isso é fundamental para quem lida com grandes volumes de dados e precisa de respostas rápidas.
Por Que Usar PDTs? Os Benefícios São Claros
O Looker trabalha diretamente com o seu banco de dados. Quando suas análises envolvem junções pesadas ou agregações complexas, a performance pode cair. As PDTs entram em cena para resolver isso, armazenando resultados intermediários e trazendo uma série de vantagens:
- Performance Turbinada: Pré-calcula os resultados para evitar consultas pesadas e repetitivas.
- Lógica Reutilizável: Defina uma vez e use em múltiplos dashboards e explorações.
- Atualização Inteligente: Controlada por gatilhos ou agendamentos, garantindo que os dados estejam sempre em dia.
- Complexidade Simplificada: Perfeito para agregações em várias etapas ou junções complicadas.
- Aproveita o Poder do seu Warehouse: As PDTs são armazenadas diretamente no seu banco de dados existente.
Como as PDTs Funcionam na Prática
O fluxo é bem direto: o Looker executa o SQL definido no bloco derived_table. O resultado é então materializado, ou seja, salvo como uma tabela física no seu banco de dados, geralmente com um nome seguindo um padrão como _looker_tmp_abcdef1234. O Looker reutiliza essa PDT até que o tempo de validade (definido por persist_for) expire, ou até que um gatilho de datagroup ou uma dependência force uma atualização.
Criando Sua Primeira PDT
Para criar uma PDT, você define a lógica SQL em um bloco derived_table e especifica por quanto tempo essa tabela deve ser mantida válida usando o parâmetro persist_for. Após esse período, o Looker a reconstruirá automaticamente.
Exemplo:
view: customer_summary {
derived_table: {
sql: SELECT c.id AS customer_id, c.name, COUNT(o.id) AS total_orders, SUM(o.total_amount) AS total_revenue FROM analytics.customers AS c LEFT JOIN analytics.orders AS o ON c.id = o.customer_id GROUP BY 1, 2 ;;
persist_for: "24 hours"
}
dimension: customer_id { primary_key: yes }
dimension: name {}
measure: total_orders { type: sum; sql: ${TABLE}.total_orders ;; }
measure: total_revenue { type: sum; sql: ${TABLE}.total_revenue ;; }
}
Neste exemplo, a PDT customer_summary será recriada a cada 24 horas.

Configurando o Esquema para PDTs
Para que as PDTs funcionem, sua conexão com o banco de dados precisa permitir escritas. Você deve ir em Admin → Connections → Sua Conexão e habilitar a opção PDTs Allowed (Temp Schema Writable), especificando um nome para o esquema onde as PDTs serão armazenadas (ex: looker_tmp). Após testar e salvar, o Looker utilizará esse esquema.
Gatilhos de Atualização com Datagroups
Quer que suas PDTs sejam atualizadas automaticamente quando os dados de origem mudarem? Use datagroup_trigger. Ele permite definir um SQL que, quando executado e detectada uma mudança (como o MAX(updated_at) de uma tabela de pedidos), força a reconstrução da PDT.
Exemplo:
datagroup: orders_refresh {
sql_trigger: SELECT MAX(updated_at) FROM analytics.orders ;;
max_cache_age: "12 hours"
}
view: sales_summary {
derived_table: {
sql: SELECT region, SUM(total_amount) AS total_sales FROM analytics.orders GROUP BY 1 ;;
datagroup_trigger: orders_refresh
}
}
Monitorando Suas PDTs
Fique de olho na saúde das suas PDTs! Na seção Admin → SQL Runner → Manage PDTs, você pode verificar o status de construção (Sucesso, Falha, Em Andamento), reconstruir manualmente ou remover PDTs antigas. O sistema também oferece um Explore em Looker System Activity → PDT Builds para um monitoramento mais detalhado.
PDTs Incrementais: Ideal para Big Data
Para datasets realmente grandes, reconstruir uma PDT inteira pode ser ineficiente. As PDTs incrementais resolvem isso, adicionando apenas os novos dados em vez de refazer tudo. Elas usam um increment_key para identificar o que precisa ser atualizado.
Exemplo:
view: daily_sales_summary {
derived_table: {
sql_trigger_value: SELECT MAX(updated_at) FROM analytics.sales ;;
increment_key: "order_date"
sql: SELECT order_date, SUM(amount) AS total_sales FROM analytics.sales WHERE order_date >= CURRENT_DATE - INTERVAL 7 DAY GROUP BY 1 ;;
persist_for: "24 hours"
}
}
Aqui, apenas os 7 dias mais recentes de vendas serão atualizados e adicionados.

Dicas de Performance e Boas Práticas
- Use PDTs para junções pesadas, agregações complexas ou modelos multi-banco de dados.
- Evite PDTs para datasets pequenos e simples.
- Prefira
datagroup_triggerquando a frescura dos dados depende das fontes. - Teste seu SQL no SQL Runner antes de convertê-lo para PDT.
- Documente as dependências para evitar problemas de reconstrução em cadeia.
- Otimize seu SQL: pré-filtre e agregue o mais cedo possível.
- Documente suas PDTs com descrições claras.
- Use convenções de nomenclatura consistentes.
- Monitore os tempos de build e falhas na área de Admin.
- Agende reconstruções para horários de menor pico, se possível.
Exemplo Real: Resumo de Campanhas de Marketing
Imagine juntar dados de impressions, clicks e conversions para criar um dashboard diário de métricas de campanha. Uma PDT pode pré-agregar esses dados, garantindo que o dashboard carregue instantaneamente.
Resumo e Pontos-Chave
As PDTs são ferramentas essenciais para escalar a performance no Looker, especialmente para transformações e agregações complexas. Gerenciar e monitorar suas PDTs ativamente, combinar com datagroups para atualizações inteligentes e manter seu SQL otimizado são práticas que garantem o máximo de eficiência.

Em resumo, as PDTs são um componente vital para quem busca análises de dados rápidas, eficientes e escaláveis no Looker.
chat_bubble Comentários (0)
Nenhum comentário ainda. Seja o primeiro a comentar!
Deixe seu comentário