Turbine a Descoberta de Dashboards: A Magia do Looker com BigQuery ML
Seus usuários do Looker batem cabeça na hora de achar aquele dashboard essencial? Em ambientes corporativos onde os relatórios se multiplicam, a busca por palavras-chave já não resolve. O resultado? Frustração e tempo perdido. Mas e se houvesse um jeito mais esperto de encontrar o que você precisa?
Apresentamos uma solução novinha em folha: um motor de recomendação de dashboards para o Looker turbinado por embeddings do BigQuery ML (BQML). Esqueça a busca literal; vamos mergulhar no significado por trás das suas consultas.
O Poder da Busca Semântica
Neste guia, vamos implementar uma estratégia de "Dense Search". A ideia é alimentar o modelo de embeddings com o conteúdo bruto do dashboard: títulos, descrições e até as queries. Isso captura a essência semântica, permitindo que um usuário procure por "vendas" e encontre dashboards de "receita", por exemplo. É um achado!
Mas atenção: para um sistema profissional, o ideal é ir além. Discutiremos como evoluir para uma "Hybrid Search", combinando essa busca semântica com a tradicional busca por palavras-chave. Assim, metadados técnicos específicos, como nomes de colunas, também entram no jogo.
Construindo Seu Motor de Recomendação: Visão Geral
Criar esse motor é um processo direto que une Looker, BigQuery e BQML. O fluxo principal é:
- Coleta de Conteúdo: Identifique as pastas do Looker com os dashboards que você quer indexar.
- Extração de IDs: Use a API do Looker para pegar os IDs dos dashboards.
- Armazenamento de Metadados: Junte todas as informações importantes dos dashboards. Vamos serializar o JSON completo para uma análise profunda.
- Geração de Embeddings com BQML: Utilize o BQML para transformar esses metadados em vetores numéricos (embeddings).
- Busca Vetorial: Uma consulta SQL simples para buscar nos embeddings gerados.
- Integração: Conecte tudo a um modelo LookML ou a uma interface de chat com IA. Já deu uma espiada na demo do nosso Embedded Analytics App Template? O GIF abaixo dá um gostinho!
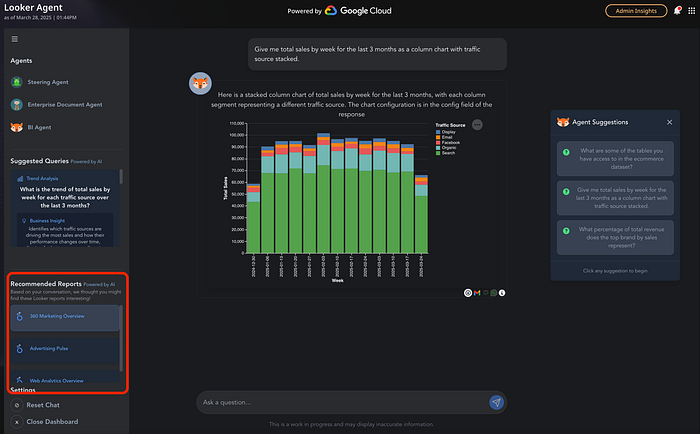
Com isso, seus usuários vão poder buscar dashboards usando linguagem natural, encontrando o que precisam pela intenção, não só pelas palavras exatas.
Mãos à Obra: Pré-requisitos e Configuração Inicial
Para começar essa jornada, você vai precisar de:
- Um notebook no Google Colab.
- Uma instância do Looker configurada.
- Acesso a um projeto Google Cloud com a API do BigQuery habilitada.
- Permissões IAM para criar datasets, tabelas e conexões remotas no BigQuery, aproveitando os recursos do Vertex AI.
Com tudo pronto, vamos definir algumas variáveis essenciais no seu notebook:
PROJECT_ID = "" #@param {type: "string"} # Insira o ID do seu projeto Google Cloud
DATASET_ID = "" #@param {type: "string"} # Insira o ID do seu dataset no BigQuery
TABLE_ID = "dashboard_metadata" #@param {type: "string"} # Nome da tabela para metadados
EMBEDDINGS_TABLE_ID = "dashboard_metadata_embeddings" #@param {type: "string"} # Nome da tabela para embeddings
REGION = "us" #@param {type: "string"} # Região para a conexão remota
BQML_REMOTE_CONNECTION_NAME = "dashboard_recommendation_system" #@param {type: "string"} # Nome da conexão remota BQML
MODEL_NAME = "dashboard_embeddings" #@param {type: "string"} # Nome do modelo de embeddings BQML
Autentique seu notebook no GCP se estiver usando o Colab:
from google.colab import auth
auth.authenticate_user()
!gcloud auth login
Instancie o cliente do BigQuery:
import google.cloud.bigquery as bigquery
client = bigquery.Client(project=PROJECT_ID)
Agora, vamos configurar o SDK do Looker. Você precisará de um arquivo `looker.ini` montado no seu Colab. Consulte a documentação da API do Looker para o formato correto.
import looker_sdk
sdk = looker_sdk.init40('./looker.ini')
2. Buscando Pastas e IDs de Dashboards no Looker
Com o SDK do Looker pronto, é hora de encontrar nosso conteúdo. Precisamos definir onde procurar (em uma pasta específica, todas as pastas, múltiplas instâncias) e o que queremos como retorno (apenas dashboards, apenas looks, ambos).
Neste tutorial, focaremos em dashboards dentro de pastas específicas. Ajuste os filtros conforme sua necessidade, consultando a documentação da API do Looker. Lembre-se que essas chamadas são feitas sob a perspectiva de um único usuário; pode ser necessário adaptar para lidar com permissões de acesso variadas.
folders = sdk.search_folders(parent_id=1, fields="id,name,dashboards")
folder_ids = ",".join(map(lambda folder: folder["id"], folders))
dashboards = sdk.search_dashboards(
folder_id=folder_ids,
)
3. Extraindo Metadados para Embeddings
Para que nosso motor de recomendação seja eficiente, precisamos extrair informações descritivas valiosas.
A Abordagem "Naif" (Mas Poderosa)
Aqui, adotamos uma estratégia abrangente: juntamos títulos, descrições, campos de query e filtros em um único objeto JSON. Essa é a base da nossa "Dense Search", onde o modelo de IA aprende as relações entre esses dados implicitamente.
import json
import concurrent.futures # Para processamento paralelo
from google.cloud import bigquery
def extract_relevant_metadata(dashboard_json):
"""
Extrai metadados relevantes de um objeto JSON de dashboard do Looker para gerar embeddings.
Args:
dashboard_json (dict): Um dicionário representando o JSON do dashboard Looker.
Returns:
dict: Um dicionário contendo os metadados extraídos, pronto para embedding.
"""
extracted_data = {
"dashboard_title": dashboard_json.get("title", ""),
"dashboard_description": dashboard_json.get("description", ""),
"dashboard_id": dashboard_json.get("id", ""),
"elements": []
}
for element in dashboard_json.get("dashboard_elements", []):
element_data = {
"element_title": element.get("title", ""),
"element_type": element.get("type", ""),
"body_text": element.get("body_text", ""),
"query_fields": [],
"query_filters": [],
"query_model": None,
"query_view": None,
"listen_filters": []
}
if element.get("query"):
query = element["query"]
element_data["query_fields"] = query.get("fields", [])
element_data["query_model"] = query.get("model", None)
element_data["query_view"] = query.get("view", None)
filters = query.get("filters", {})
element_data["query_filters"] = [f"{field}: {value}" for field, value in filters.items()] if filters else []
if element.get("result_maker"):
result_maker = element["result_maker"]
if result_maker.get("filterables"):
filterables = result_maker.get("filterables")
for filterable in filterables:
if filterable.get("listen"):
listens = filterable.get("listen")
for listen in listens:
element_data["listen_filters"].append(listen.get("dashboard_filter_name", None))
extracted_data["elements"].append(element_data)
return extracted_data
def process_dashboard(dashboard_json):
"""Processa um único JSON de dashboard e extrai metadados.
Esta função é projetada para ser usada como um worker em um pool de processamento paralelo.
"""
try:
return extract_relevant_metadata(dashboard_json)
except Exception as e:
print(f"Erro ao processar dashboard: {e}")
return None
def insert_into_bigquery(data_list, project_id, dataset_id, table_id):
"""Insere uma lista de dicionários de metadados extraídos em uma tabela do BigQuery."""
try:
client = bigquery.Client(project=project_id)
table_ref = client.dataset(dataset_id).table(table_id)
schema = [
bigquery.SchemaField("metadata", bigquery.enums.StandardSqlTypeNames.JSON),
]
rows_to_insert = [{"metadata": data} for data in data_list]
errors = client.insert_rows(table_ref, rows_to_insert, selected_fields=schema)
if errors:
print(f"Erros encontrados ao inserir linhas: {errors}")
else:
print(f"Inseridas {len(data_list)} linhas com sucesso em {project_id}.{dataset_id}.{table_id}")
except Exception as e:
print(f"Erro ao inserir no BigQuery: {e}")
def main():
"""Função principal para processar múltiplos dashboards em paralelo e inserir no BigQuery."""
# --- Processamento Paralelo ---
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
results = list(executor.map(process_dashboard, dashboards))
extracted_metadata_list = [r for r in results if r is not None]
# --- Inserir no BigQuery ---
insert_into_bigquery(extracted_metadata_list, PROJECT_ID, DATASET_ID, TABLE_ID)
main()
Conclusão
Criar um motor de recomendação de dashboards com Looker e BigQuery ML é um passo gigante para otimizar a descoberta de informações. Ao ir além da busca por palavras-chave e abraçar a busca semântica, você capacita seus usuários a encontrar insights mais rapidamente, aumentando a produtividade e o valor dos seus dados.
chat_bubble Comentários (0)
Nenhum comentário ainda. Seja o primeiro a comentar!
Deixe seu comentário